Structuring Data Science Part 1 (the Doc2Vec route)
I have found an issue in my learning of data science, that navigating through all the material is somewhat of a nightmare especially when starting out. We are at a time where we have a prodigious volume of learning material out there be it blogs, videos or open source papers. The problematic I find is that there almost exists too much material today, it becomes a nightmare to navigate all the content, where do you start, which subjects are connected to one another, where should I go next and what is fundamental to understand about each subject. My project started as something quite simple, in the fact that I was reading a paper in data science and coming from an engineering background I did not necessarily understand all the concepts required to fully understand the paper and beyond this I believe in canonical learning - going to the root - and doing this in Data Science is somewhat difficult.
The reason - and I will give my 2 cents regarding this - is that data science is an amalgamation of so many different domains that it is in its nature ill defined and evolving. As such the subject is exceptionally different to interpret and access from the outside.
Fundamentally, for me I saw this huge reservoir of resources online but no good or structured way to navigate it, out of the hundreds of blogs to read - which to read. An issue is there is such a breadth of subjects that you can quickly become familiar with 100s of “Data Science” terms (Deep Learning, ANN, SVMs…) without having any degree of understanding of those concepts. Google is great when you have a specific question but trying to navigate a domain is more difficult you don’t want the best match but the underlying web. In addition, Wikipedia is a fantastic resource, however, it has too many options, it is too unconstrained and only text based.
My plan initially was to take a paper, write a program to extract its concepts and link it to videos which match closely to the concepts of the paper. In addition, based on this to look to construct a document hierarchy based on the concept similarity of documents.
As you will find out, my first attempt was maybe not the most fruitful, in terms of end objectives, even if it taught me a great deal regarding the various techniques out there, I also saw a limitation in any set of methods which try to become completely unsupervised. So if you just want to know the way that worked finally and allowed me to obtain my objective go to part 2.
What did I achieve
I hit one of my two objectives, I achieved document similarity and sensible document recommendations. What I did not achieve was good categorization of documents.
The Processing
Prior to all my stages of data science analysis, I had a massive if underwhelming data science scraping phase, where I took around 2000 papers from Arxiv which were under various search terms related to data science (data science, machine learning). In addition, using Selenium (there is a better way with youtube-dl, but I did not realize at the time) I scraped Youtube for their transcripts, in all taking around 400 hrs of video transcripts. After this came the exciting stuff… In essence to achieve my analysis I used Doc2Vec to create document vectors for each of the documents or video transcripts. Once I had individual vectors for each of the documents I used recursive K-means clustering to divide my document vectors into sets, each time splitting each subset into a smaller subset creating a 5 deep hierarchy. This left me with approximately 3000 subsets which were all linked to master nodes. Now the problem I faced is this unsupervised technique of splitting my documents created a sort of concept hierarchy, but each of these concepts remained unnamed. In order to name these clusters I used a separate methodology where for each of these clusters I used TFIDF combined with NMF. This allowed me to yield a subset of words which defined concepts, from this I used the top 5 set of words from the highest concept to define the name of the cluster.
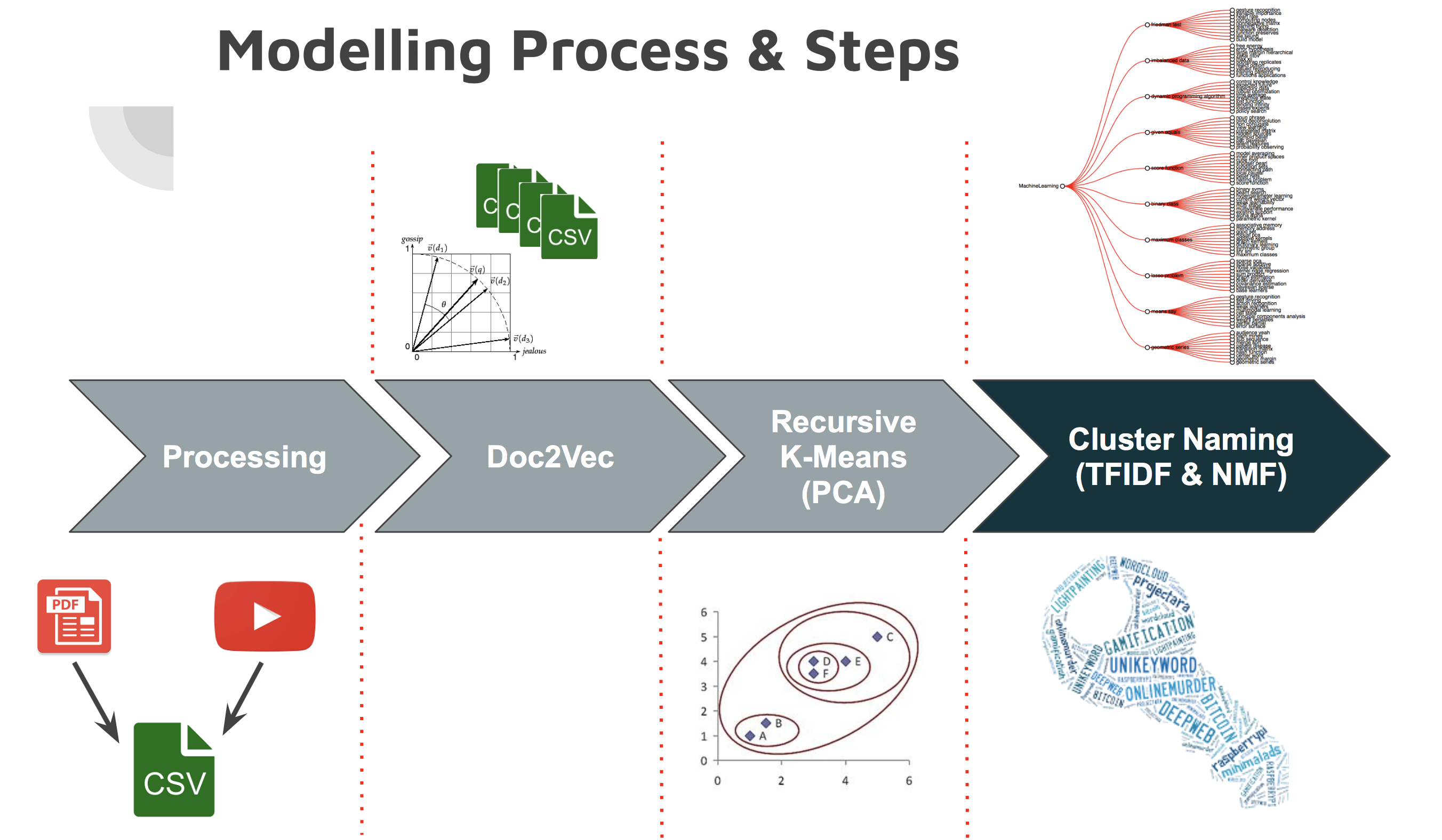
The reflections
This methodology allowed me through the integration of two techniques to develop an unsupervised methodology to cluster documents and also derive concepts from them. Which for me is a pretty cool thing, given a corpus of documents which have some sort of underlying links between them, you can develop a hierarchy. I mean it is in essence a presence under the bias, that at the top level all documents only have similarity at their most basic levels (statistics, mathematics…) and at the deeper levels as the documents cosine similarity approaches then the documents should get to have a finer level of concept matter.
Unfortunately the reality was that although the document clustering worked, the documents were just a mess of concepts there were too many links to create coherent clusters in this methodology. In addition, although during my bias (tired moments) I believed there to be coherent cluster names, it was not high enough in accuracy, the clusters often didn’t make sense, or contained lower level subjects (inspect the network tree above). This sort of method although nice and clean, was not working.
At the top is a D3 showing the hierarchy created. Also, below I show some of the cases which work, but also the inadequacy of the models when it comes to video recommendations. The percentage is the similarity score, but it is clear that 1) videos, I had an insufficient corpus to derive good recommendations for each paper and 2) the model I setup did not do a good enough job at finding relationships between text content.

Also, during the process of putting together this model I did try a method of using LDA, in order to derive topics from the overall corpus as we can see there are again some sensible concepts but the problem in this technique originated from my tokenization and parsing methodologies. In order to get this working, I need to achieve a much better method of excluding unimportant words and n-grams, in particular names, introduction of POS and NER would be useful, but in the next strategy I will also look at application of a knowledge base to improve the quality of the concepts.
You can play with the results of LDA in the visualisation at the bottom of the page.
The forward plan
So what I realised and is that this method will ultimately achieve limited accuracy. Documents are not a hierarchy but an ontology, I actually believe documents should be treated as twitter posts with multiple hashtags. An individual document sits in a web of concepts and is connected through multiple edges to these concepts. The weight of the edges depend on the level of similarity this document resembles to that concept. This is the way I needed to approach it, I needed to develop document ontologies, not single hierarchies. The power of this is also that it achieves my second objective which is that I believe that humans themselves are poor at defining and tagging documents, it depends on where you come from, if you come from a more statistical background you will tag differently a document, post it in a different journal or repository than a computer scientist, and the problem is that these functional domain barriers create separation of content which is inherently similar. Therefore, describing an ontolgy through the topics covered in a document will allow for domains to be broken down and only their edges to be observed.
WEll so this leads to my second iteration…to follow in a second blog as I explore new methods to achieve a structure to the web of data science resources.
Tools used
-For this Sklearn was used for tokenization and the overall NLP pipeline.
-Selenium was used to scrape youtube transcripts. -PDF parsing and conversion to CSV was achieved using pdfminer -Visulisations achieved using D3 and pyLDAvis
All code available on my github: Click Here
