Managing my finances - How to link Spending and Location?
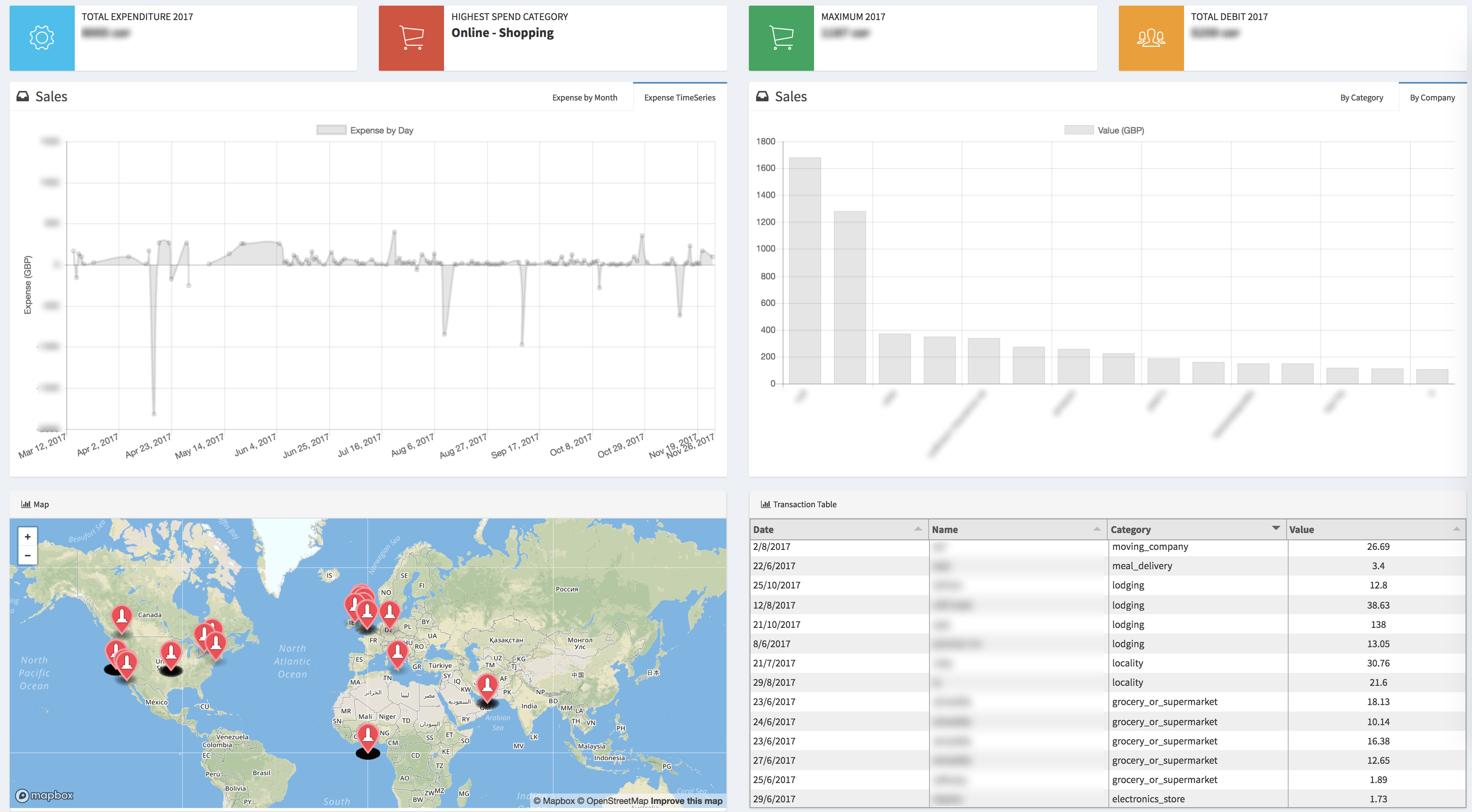
Snapshot
I cover an ongoing project with the objective of creating a better budgeting and personal expenditure platform. I have created a program which takes all my credit and debit card statements and by combining it with my phones location, label each transaction with a location and a type (eating-out,shopping…). This allows me to aggregate my expenses much more clearly by understanding how I spend money. It also allows me to integrate all my bank accounts into one dashboard for an analysis, giving me one platform for an overview of my finances. Below I have given an overview of the initial implementation I have chosen to transform the simple bank statement into a more insightful set of numbers.
A link to the Git repo is here
Objectives and Reasons
So I have a problem derived from spending many years working in different locations, I spend in different locations and different currencies and with banks in different countries. In addition, I have the problem that personal budgeting has never been a forte of mine. I recently subscribed to a bank called Monzo, it offers a prepaid card, and the app it offers is really pretty nifty. One of its many features is that when you look at your expenses, it categorizes it by type (shopping, eating-out etc.) it also geo-locates your expense. I find this pretty useful, as what I like to look at is a breakdown of my expenses, and also where am I spending this money.
Now since Monzo is just a prepaid card, it cannot be integrated into my day to day banking. But I thought why not look to achieve something similar with my own statements. Take my statements from online and then map the type of expense to it as well as the location that I spent the money. Giving me the ability to better aggregate my expenses by location and by type. Giving me lots of ability to achieve historical analysis of my expenses and in general see my expenditure trends. Now a big issue also is I didn’t want to sit and manually label thousands of data sets so I wanted to achieve this with at least a semi-unsupervised technique.
Implementation
My method to achieve mapping type and location I used the credit card statement to derive the companies name and then I used my phones location (downloaded straight from Google) to then map approximate locations to these expenses. Then based on an approximate location and the companies name where I spent the money I queried Google’s Places API in order to find establishments matching the criteria. Now sounds simple, but turned out to be a bit more involved to get good accuracy. This was for two primary problems firstly descriptions in credit card statements are ambiguous (they rarely just state the companies name), secondly an expense is logged by day with no time associated with it, so which of the on average 100 locations which Google logged me at per day (yes, over 6 months I had about 120 000 distinct coordinates, quite scary).
There are of course further problems like, what to do for online companies, what to do for companies with numerous establishments there are quite a few Peet’s in San Francisco. Before I delve into the details I would just like to grind a gear, that all this inherent data, exact location and type of business, is in the systems of the banks, it is quite infuriating not to have this on my statement. This seems like a lot of effort just to record and track my expenses.
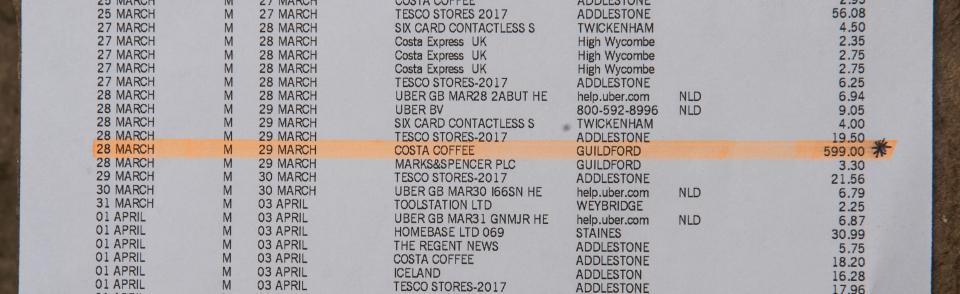
Getting the companies name
When you download the CSV file from your bank it has a general description of the expense which relates to your transaction but it is not in plain english. The below examples are quite common:
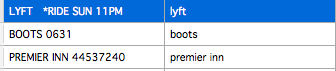
Now you and I are able to decipher this out because it is us who spent the money. But getting a systematic method to get a computer to parse out which part of the description was the company is not quite as easy and relied on several layers of modeling and parsing techniques. In addition, in order for the system to be robust it needs to be able to disambiguate Amazon EU = Amazon UK = AMZEU = AMZiggolo. All these expenses are from Amazon which should be classified as online-shopping. I set out an objective to minimize the number of terms I would need to predefine. Unfortunately there are just too many variations and possible expenses that it becomes important to be able to automatically extract similarities and to identify the part related to the company. In addition, I have a further constraint that Google allows me to use about 2500 api calls per day, so I want to make sure the API call I make has the highest likelihood of getting a response and it would be impractical to query all variants of the name.
In order to achieve this I tried a purely heuristic model with certain rules based on the text, I did the following:
- For each description tokenize the word and score each word for its likelihood of being part of the companies name
- Inspect the length of the word, if longer that 5 letters it is more likely to be a word.
- Check if the word is in the dictionary (+1 point). It is at least a word.
- Check if there are any embedded words in tokens longer than three letters. A token is more likely to represent a word if it in fact does itself contain a word, and if it is an actual word then it is more likely to form part of the companies name.
- Previous word frequency, common expenses for example Starbucks may appear on the statement as such “Starbucks z0Jan17” but the word Starbucks will have a higher frequency if I have often gone to Starbucks. The noise around the companies name will change but the name will be the constant.
- Previous phonetics, now this is less important for company name identification, but is more important in the disambiguation. I use fuzzy with depsan2 to create a phonetic representation for each word and see how often that phonetics occur. Actually using phonetics is quite useful as for example AMZ = Amazon and there 3 character phonetic representation is the same and often when it comes to looking for acronyms we look for phonetic similarity.
- Word structure, how many vowels and consonants, a token with 2 or more vowels and more consonants is more likely to represent a word.

Disambiguation
At this step after step one I have the predicted company name, but this could have multiple representations for the same company i.e. AMZ, Amazon, Amazon eu In order to relate these and its variants together I used a number of techniques and if all 3 conditions were satisfied the company was declared a subset of the others:
- Phonetic representation, I looked at the phonetic representation of the first word and see if this matches any other in the company list.
- Check if all the letters of one companies name is in the others, for example {A,M,Z} intersects {A,M,A,Z,O,N}.
- Check if the first letter is the same. Simple but pretty important.
Location of the expenses
In essence for the google query I need to feed in a location and a company name. Now the problem is that my google locations file contains maybe a hundred visited locations on a given day. So what I do (and this is crude, I wish to implement possibly a k-means approach) is I pick from the database of visited location for the day of the expense, one distinct location (this should hopefully give me at least the city I am in). I send this along with the predicted companies name to google. Now google responds with a json, with a number of results matching my query. I take the results of this each of which is a distinct company with GPS coordinates, and I calculate an array with each possible company and its distance to each of the locations I visited on the day of the expense. This means that hopefully if Google has done a good job of tracking me then when I look for the smallest distance it will likely be the location I visited.
Further Improvement
This is an initial version of the code, much progress is going to be achieved. Particularly in the company name recognition. I plan to move to a Naive Bayes approach, once I can develop a labelled corpus of text to parse. Naive Bayes will be my first go to, since I am unlikely to develop an extensive corpus (as I will be making it) of labelled examples. Below I have listed a few additional improvements which will come soon:
- Dashboard
- K-means clustering of locations, to decide GPS coordinates of location (replacing distinct). This is to overcome the problem of multiple cities/countries in a single 24hr period.
- Reduce API queries through remembering previous visited locations and querying name and location.
- Augment defined company types with existing databases.
Tools/Packages used
- Python and standard numerical packages
- Fuzzy (for phonetics)
- Sqlite3 (local database system)
References
- Using fuzzy for matching with sounds [http://www.informit.com/articles/article.aspx?p=1848528].
